背景
从网上下载了烟草相关的数据及论文,想自己复现论文。论文地址
2025年9月的时候看到GPT说如果只是在Python中使用CUDA,可以直接在Anaconda中装Pytorch官方的命令行
先在Anaconda中安装Pytorch。然后用这段代码看Pytorch的版本
import torch
print(torch.__version__)
Pytorch官方的命令行中找出对应的命令行安装就行,简单,不用看CUDA和CUDNN的版本(不过还是要先更新显卡驱动,使用nvidia-smi确保安装的CUDA版本显卡支持)
安装成果后可以用一下代码测试
# -*- coding: utf-8 -*-
"""
快速检查 CUDA 是否可用(支持 PyTorch 和 TensorFlow)
"""
def check_pytorch():
try:
import torch
print("=== PyTorch CUDA 检查 ===")
print("CUDA 是否可用:", torch.cuda.is_available())
print("GPU 数量:", torch.cuda.device_count())
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
print(f"设备 {i}:", torch.cuda.get_device_name(i))
print()
except ImportError:
print("未安装 PyTorch,跳过检查。\n")
def check_tensorflow():
try:
import tensorflow as tf
print("=== TensorFlow CUDA 检查 ===")
gpus = tf.config.list_physical_devices('GPU')
if gpus:
print("检测到 GPU:", gpus)
else:
print("未检测到 GPU")
print()
except ImportError:
print("未安装 TensorFlow,跳过检查。\n")
if __name__ == "__main__":
check_pytorch()
check_tensorflow()
步骤
1 安装CUDA
通过命令行查看能够安装的最高CUDA版本,然后下载一个低于该版本的CUDA包
nvidia-smi
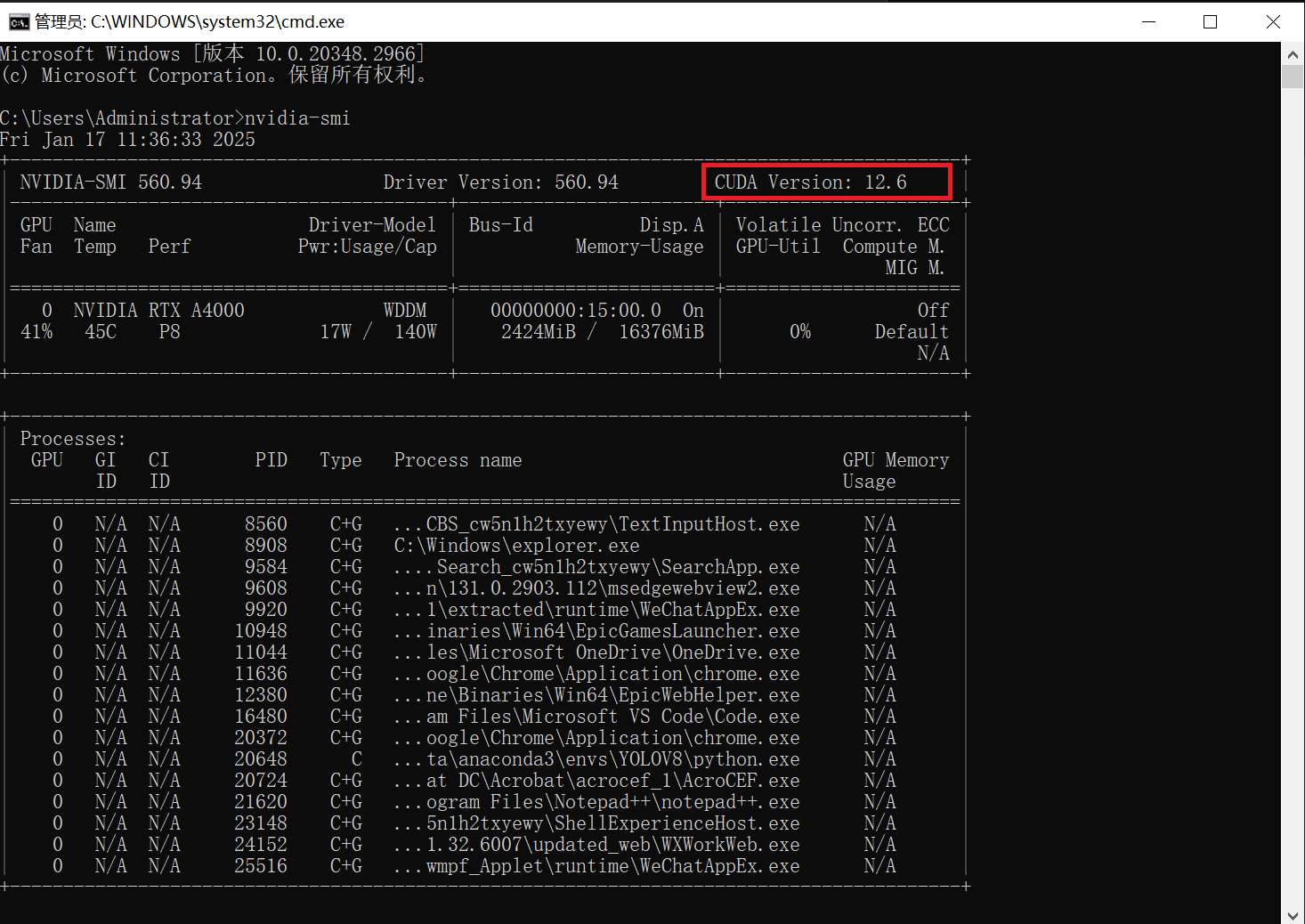
在NVIDA官网下载对应的操作系统和CUDA包。下载完成后默认简单安装即可。 历史版本
2 安装 CUDNN
需要根据CUDA的版本下载对应的CUDNN,本文下载了CUDNN8.9.7在CUNDD官网下载对应版本的CUDNN。
载完成后解压压缩包,打开解压后的文件夹如下,同时打开C盘中存放CUDA的文件夹C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4。打开后将cuDNN文件夹中bin、include、lib的文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4文件夹中对应名称的文件夹中。
运行deviceQuery.exe,验证CUDNN是否安装成功。
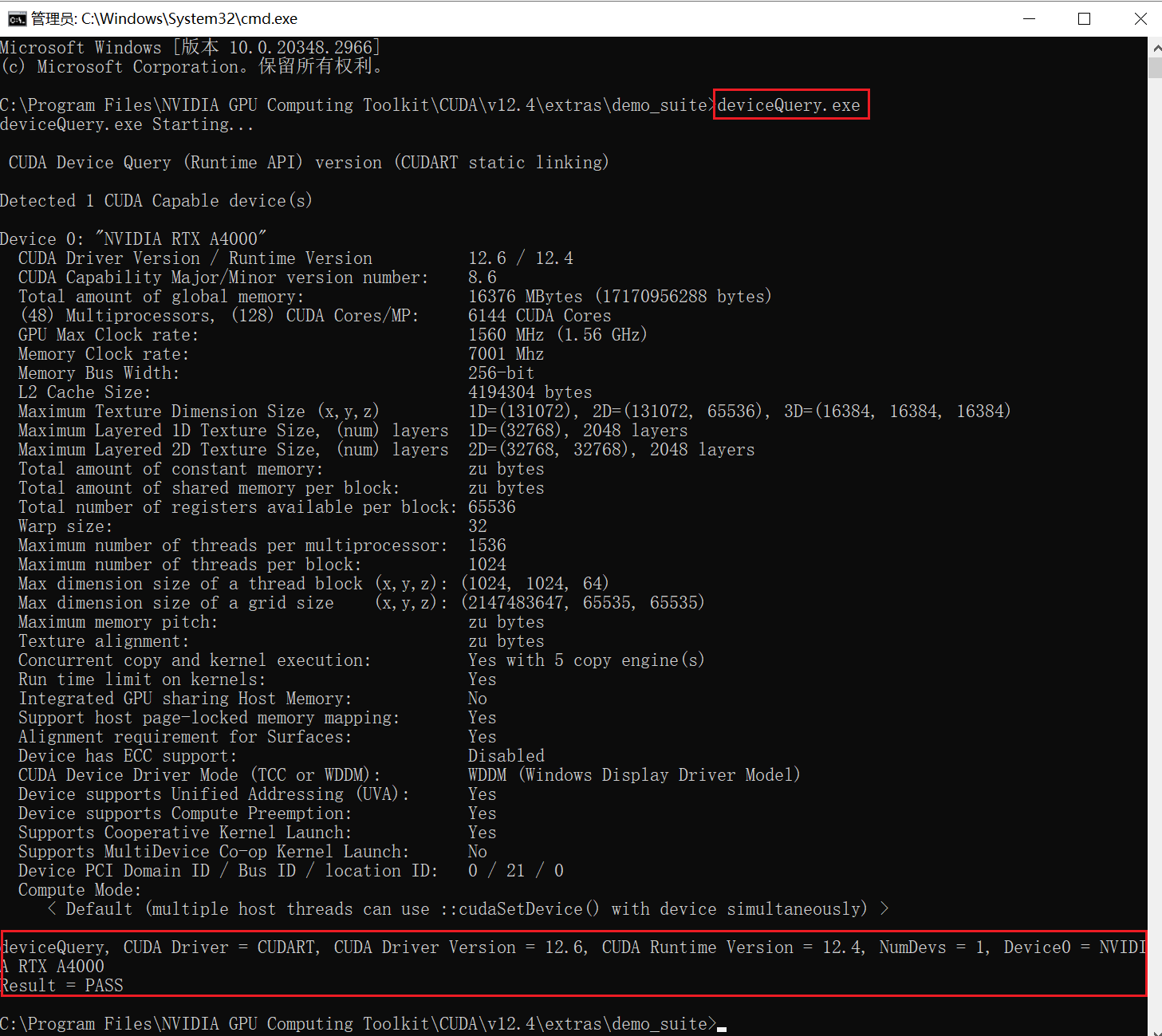
3 创建虚拟环境
使用anaconda创建虚拟环境,建议Python版本3.8以上,本文使用了3.8.20
4 安装 PyTorch
在官网选择操作系统,版本,语言和CUDA的版本,会自动生成对应的命令,直接在命令行中运行即可。 下图中是官网截图,由于我使用了Python3.8,所以实际安装的 PyTorch版本为2.4.1,不过这个命令是对的。
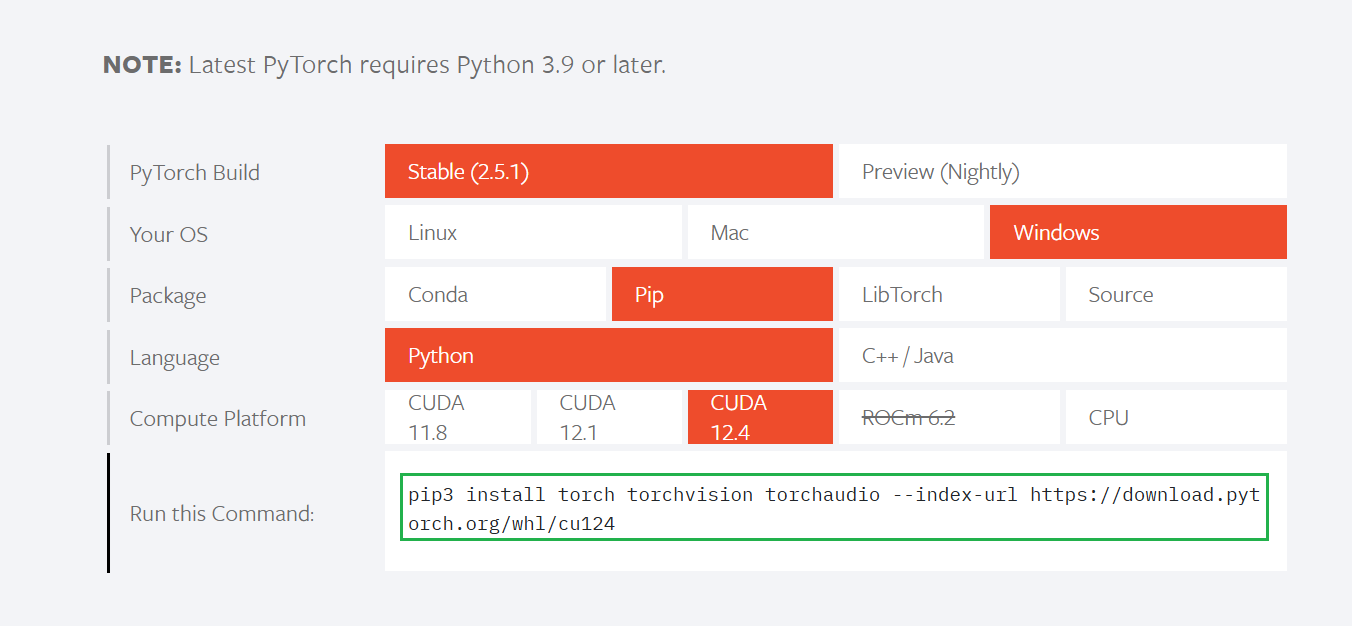
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
5 安装 ultralytics
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
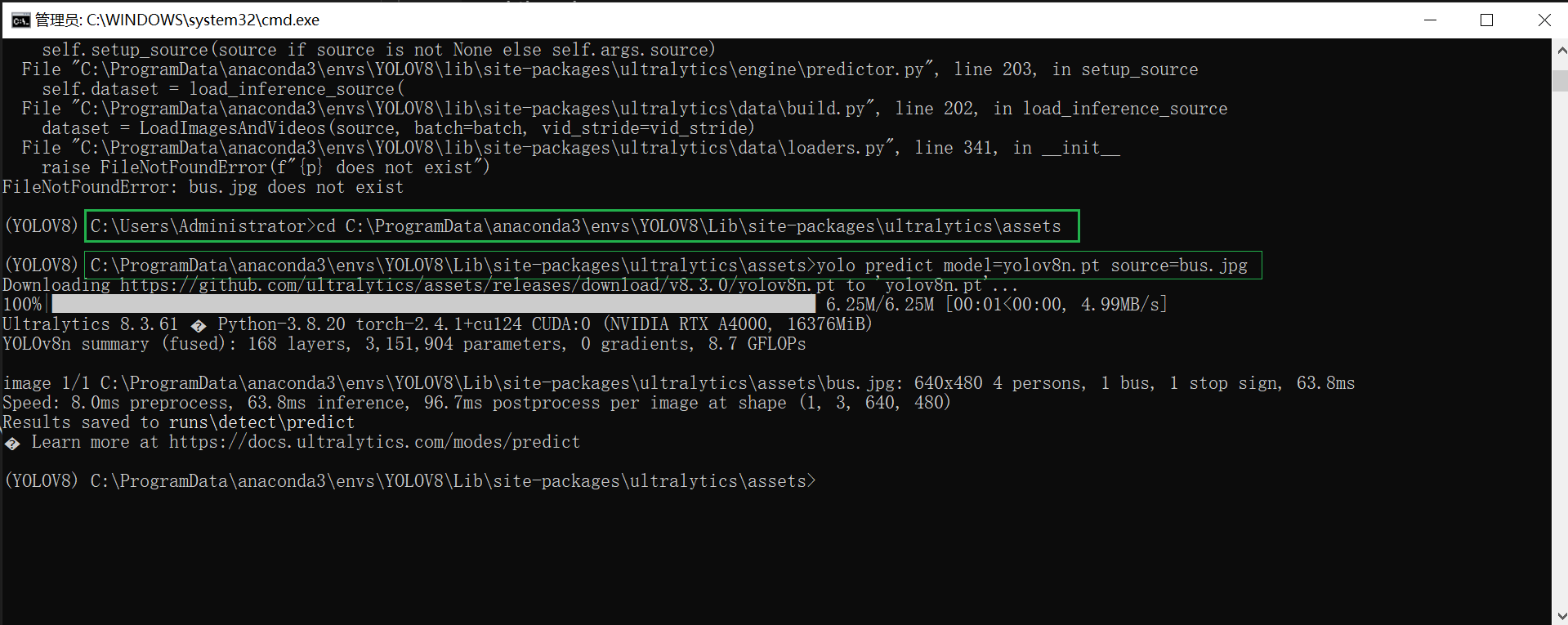
使用命令行测试是否安装成功
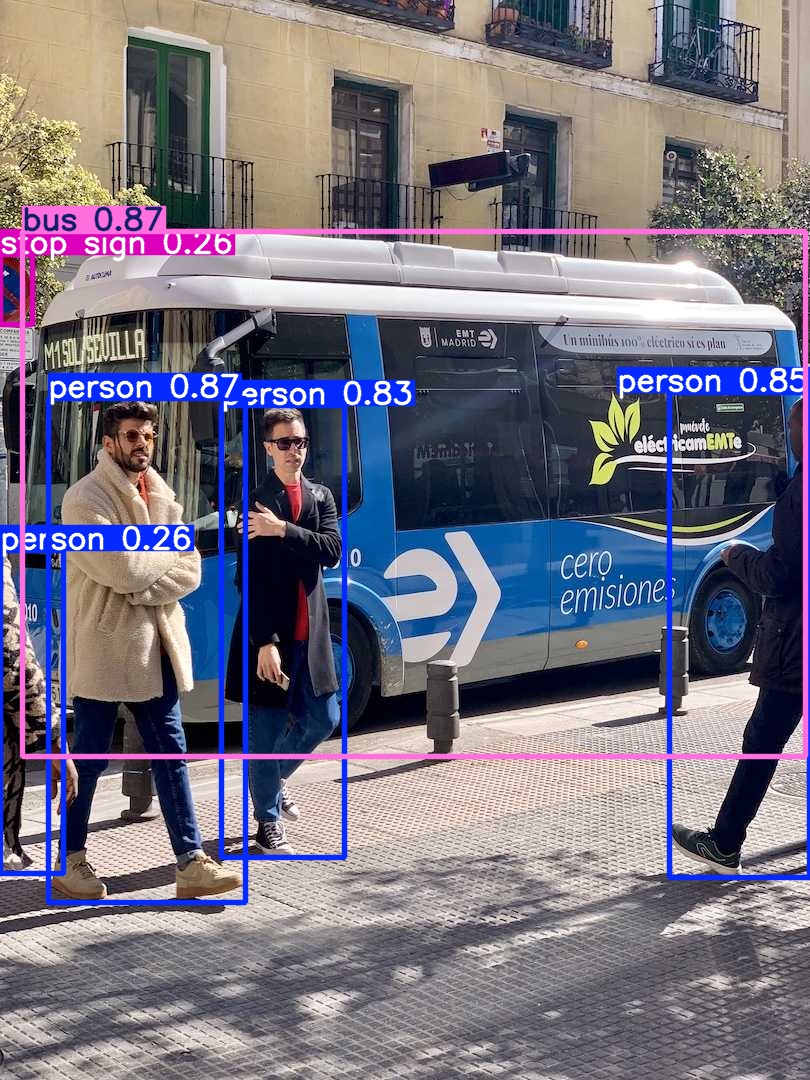
yolo predict model=yolov8n.pt source=bus.jpg
下图展示了命令行运行的结果,在run文件夹下。
6 训练和验证自己的数据
YOLO有自己的数据集格式,详见官网。可以参照贡献新的数据集格式组织自己的数据。
 以下是data.yaml文件
以下是data.yaml文件
train: M:/BaiduNetdiskDownload/DATA/TEST/datasets/train/images # 训练集图像路径
val: M:/BaiduNetdiskDownload/DATA/TEST/datasets/val/images # 验证集图像路径
nc: 1 # 类别数(根据你的数据集设置)
names: ['tobacco'] # 类别名称列表
训练代码如下:
from ultralytics import YOLO
# 1. 选择一个 YOLOv8 模型配置文件
model = YOLO("yolov8n.pt") # 可以选择 yolov8s.yaml, yolov8m.yaml, yolov8l.yaml, yolov8x.yaml
# 2. 加载数据集配置文件 (data.yaml)
data = "./datasets/data.yaml" # 你的 data.yaml 文件路径
# 3. 设置训练参数
epochs = 100 # 训练轮数
batch = 16 # 每批次训练样本数量(修改为 'batch' 而不是 'batch_size')
img_size = 640 # 输入图像的大小
device = "0" # 使用的 GPU(如果你有多个 GPU,可以设置为 "cuda:0", "cuda:1" 等)
# 4. 启动训练
model.train(data=data, epochs=epochs, batch=batch, imgsz=img_size, device=device)
# 5. 训练完成后,可以查看模型的性能(例如 mAP)并保存模型
# 最好的模型会被保存在 runs/train/exp/weights/best.pt
输入的结果截取部分如下:
results_dict: {'metrics/precision(B)': 0.9664859351677902, 'metrics/recall(B)': 0.9812629264425106, 'metrics/mAP50(B)': 0.9908947436610503, 'metrics/mAP50-95(B)': 0.705217510372213, 'fitness': 0.7337852337010968}
save_dir: WindowsPath('runs/detect/train9')
speed: {'preprocess': 0.3490924835205078, 'inference': 1.2964844703674316, 'loss': 0.0, 'postprocess': 1.3463854789733887}
task: 'detect'
可以使用增广数据的方法对训练数据进行旋转等处理,作为测试集,对模型进行测试。 增广代码:
from PIL import Image
import os
# 1. 设置文件夹路径
input_folder = r"M:\BaiduNetdiskDownload\DATA(tobacco plants using multispectral UAV)\TEST\datasets\source" # 输入文件夹路径(包含TIF图像)
output_folder = r"M:\BaiduNetdiskDownload\DATA(tobacco plants using multispectral UAV)\TEST\datasets\test" # 输出文件夹路径
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 2. 获取文件夹中所有的TIF图像
for filename in os.listdir(input_folder):
if filename.lower().endswith(".tif"):
# 构建完整的输入和输出路径
input_image_path = os.path.join(input_folder, filename)
output_image_path = os.path.join(output_folder, f"rotated_{filename}")
# 打开图像
image = Image.open(input_image_path)
# 旋转图像(例如旋转 90 度)
rotated_image = image.rotate(90) # 你可以更改旋转角度
# 保存旋转后的图像
rotated_image.save(output_image_path)
print(f"Rotated image saved at {output_image_path}")
测试代码:
# 6. 使用训练好的模型进行推理(可选)
results = model.predict(source=r"M:\BaiduNetdiskDownload\DATA\TEST\datasets\test", conf=0.25) # 对测试集进行预测
for i, result in enumerate(results):
result.save(f"output_image_{i}.jpg") # 将每个图像的预测结果保存为不同文件名

引用文献:
[1] CUDA和cuDNN安装
[2] cuda和cudnn的安装教程(全网最详细保姆级教程)
[3] 完整且详细的Yolov8复现+训练自己的数据集
[4] yolov8实战第一天——yolov8部署并训练自己的数据集(保姆式教程)